Канонічний URL не працює? 10 причин, чому Google вибирає іншу сторінку
Ви перевірили сторінку через SEO-плагін, переконалися, що канонічний URL налаштований правильно, відкрили код сторінки — і тег дійсно на місці. Здавалося б, усе працює як потрібно. Але через деякий час у Google Search Console з’являється повідомлення:
Google chose different canonical than user.
Для багатьох власників сайтів це стає неприємним сюрпризом. Особливо якщо сайт технічно доглянутий, має хорошу структуру та не виглядає проблемним.
Кілька років тому канонічний URL справді працював значно простіше. Якщо сторінка містила коректний canonical, Google у більшості випадків приймав його без зайвих питань. Але сучасний веб дуже змінився. Сайти стали складнішими, динамічнішими та значно більш перевантаженими технічними елементами.
Сьогодні типовий сайт може містити:
- багатомовні версії сторінок;
- десятки параметрів URL;
- фільтри товарів;
- автоматичну генерацію SEO-сторінок;
- JavaScript-навігацію;
- окремі мобільні блоки;
- UTM-мітки;
- динамічний контент;
- AI-згенеровані тексти.
У такому середовищі канонічний URL вже давно перестав бути “жорсткою командою” для пошукової системи. Тепер це лише один із багатьох сигналів, які Google аналізує перед тим, як визначити основну сторінку.
І якщо загальна логіка сайту суперечить canonical — Google дуже часто приймає власне рішення.
У цій статті розберемо, чому це відбувається, які помилки найчастіше зустрічаються на сучасних сайтах та як зрозуміти, чому Google ігнорує ваш канонічний URL.
Що таке канонічний URL і чому навколо нього стільки проблем
Канонічний URL — це спеціальний тег, який повідомляє пошуковим системам, яку версію сторінки потрібно вважати основною серед кількох схожих або дубльованих URL.
У класичному вигляді він виглядає так:
<link rel="canonical" href="https://example.com/page/" />Його головна задача — допомогти Google уникнути проблем із дубльованим контентом. Наприклад, коли одна й та сама сторінка доступна через кілька URL:
- зі слешем і без слеша;
- з параметрами сортування;
- через UTM-мітки;
- через фільтри;
- через пагінацію;
- або через різні мовні версії.
Але тут важливо розуміти одну ключову річ.
Канонічний URL — це не директива. Це рекомендація.
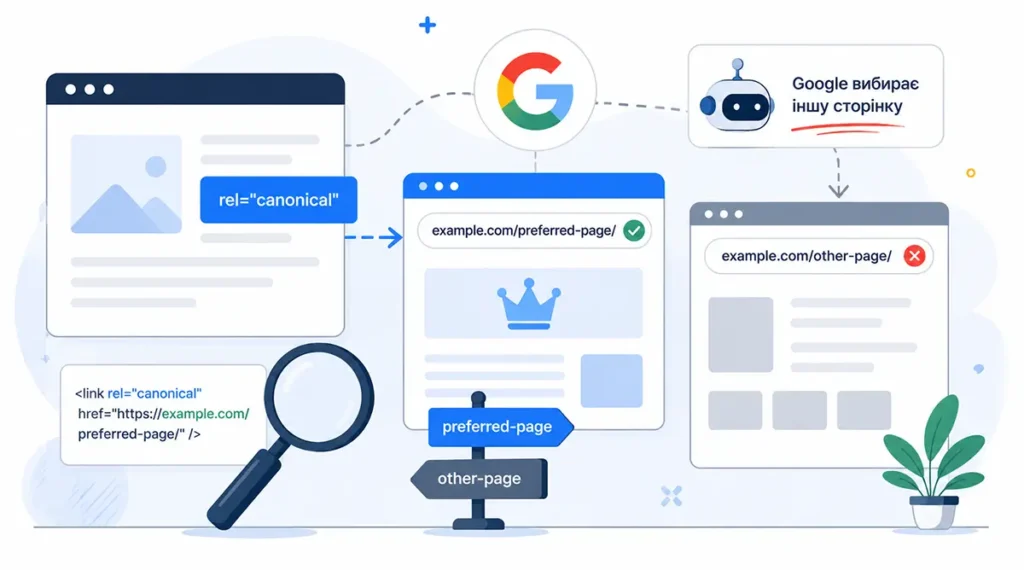
Тобто ви не наказуєте Google, яку сторінку вважати головною. Ви лише пропонуєте свій варіант. А далі пошукова система вже сама оцінює:
- структуру сайту;
- внутрішні посилання;
- контент;
- технічні сигнали;
- поведінку сторінок;
- логіку індексації.
І якщо ваш canonical суперечить іншим сигналам — Google може його проігнорувати.
Саме тому на сучасних сайтах все частіше виникає ситуація, коли SEO-плагін показує “все добре”, а пошукова система вибирає зовсім іншу сторінку.
10 причин, чому Google ігнорує канонічний URL
1. Сторінки для Google недостатньо схожі
Це одна з найчастіших причин проблем із canonical URL.
Багато власників сайтів помилково вважають, що canonical можна ставити між будь-якими “схожими” сторінками. Але Google оцінює схожість значно глибше, ніж здається на перший погляд.
Наприклад, у вас можуть бути дві сторінки категорій:
- одна — основна категорія товарів;
- інша — сторінка після застосування фільтра.
Для людини вони можуть виглядати майже однаково. Дизайн той самий, структура однакова, а різниця лише в кількох товарах.
Але Google бачить:
- інший набір товарів;
- інший текст;
- інші внутрішні посилання;
- іншу структуру контенту;
- інші сигнали релевантності.
І в результаті пошуковик вирішує:
Це не дубль. Це окрема сторінка.
Особливо часто така проблема зустрічається на великих WooCommerce сайтах, де фільтри створюють десятки або навіть сотні варіацій URL.
Наприклад:
- сторінки товарів одного бренду;
- вибір кольору;
- параметри сортування;
- сторінки зі знижками;
- окремі комбінації характеристик.
Усе це може виглядати як технічні дублікати лише для власника сайту. Але для Google це вже окремі сторінки зі своїм контекстом.
2. Внутрішня структура сайту суперечить канонічному URL
Canonical не працює ізольовано. Google оцінює сайт комплексно.
І дуже часто внутрішня структура сайту має для пошукової системи навіть більшу вагу, ніж сам канонічний тег.
Наприклад, ви вказуєте тег канонічний на сторінку:
<example.com/category/>Але при цьому:
- меню веде на URL з параметрами;
- breadcrumbs використовують іншу адресу;
- sitemap містить третій варіант URL;
- внутрішні посилання масово ведуть на дубльовану сторінку.
Для Google це виглядає як суперечливий набір сигналів.
І в такій ситуації пошуковик часто починає більше довіряти саме внутрішнім посиланням, а не канонічному тегу.
Особливо часто це трапляється після:
- редизайну сайту;
- зміни структури URL;
- міграції на інший SEO-плагін;
- встановлення WooCommerce-фільтрів;
- інтеграції сторонніх модулів.
На практиці бувають ситуації, коли canonical налаштований правильно, але половина внутрішніх посилань продовжує вести на старі URL. І тоді Google починає сприймати саме стару адресу як основну.
На практиці канонічний URL рідко працює ізольовано. Google оцінює загальну технічну логіку сайту: внутрішні посилання, sitemap, hreflang, структуру URL та доступність сторінок для сканування. Саме тому проблеми з канонічним тегом часто виявляються частиною значно ширших технічних помилок. Детальніше про це ми розповідали у статті технічна сторона сайту.
3. Конфлікт між canonical та hreflang
Для багатомовних сайтів це окрема велика категорія проблем.
Особливо часто помилки виникають на WordPress-сайтах із:
- TranslatePress;
- Polylang;
- WPML;
- кастомними мультимовними рішеннями.
Типова помилка виглядає приблизно так:
- українська сторінка має канонічну адресу англійської;
- або всі мовні версії ведуть канонічну сторінку по замовчуванню.
На перший погляд це здається логічним. Але для Google така схема створює конфлікт.
Тому що hreflang повідомляє:
Це окремі мовні версії сторінки.
А канонічний тег одночасно каже:
Ні, ось ця сторінка головна.
У результаті пошукова система отримує суперечливі сигнали та починає ігнорувати частину з них.
Особливо небезпечна така ситуація для українських сайтів, які паралельно мають:
- українську;
- англійську;
- іноді ще й російську версії.
Неправильна логіка canonical може призвести до того, що частина сторінок просто перестане нормально індексуватися.
У більшості випадків правильний варіант виглядає так:
- кожна мовна версія має self-referencing canonical;
- hreflang зв’язує мовні сторінки між собою;
- канонічний тег не “склеює” різні мови в одну сторінку.
4. Фільтри та параметри URL створюють хаос
Ще кілька років тому Google рекомендував активно використовувати канонічність для боротьби з параметрами URL. Але сучасні сайти стали настільки складними, що ця логіка вже не завжди працює.
Особливо це помітно в e-commerce.
Сучасний інтернет-магазин може генерувати сотні або навіть тисячі URL через:
- фільтри;
- сортування;
- вибір бренду;
- параметри товарів;
- pagination;
- динамічні блоки.
Наприклад:
<?filter_color=black
?orderby=price
?filter_brand=nike/>Для власника сайту це може виглядати як технічні URL, які не повинні індексуватися. Але Google дедалі частіше оцінює їх як окремі сторінки.
Чому?
Тому що:
- сторінки мають різні товари;
- змінюється структура контенту;
- з’являються інші внутрішні посилання;
- змінюється поведінка користувачів.
У деяких випадках Google навіть може вирішити, що сторінка з фільтром більш релевантна конкретному запиту, ніж основна категорія.
Саме тому канонічний URL інколи перестав бути універсальним рішенням.
Особливо часто проблеми з канонічним URL зустрічаються в інтернет-магазинах. WooCommerce, фільтри товарів, пагінація, параметри сортування та динамічні URL можуть створювати сотні технічно схожих сторінок, які Google сприймає по-різному. У результаті пошукова система починає самостійно визначати канонічні сторінки, навіть якщо canonical налаштований правильно. Більше про це можна прочитати у матеріалі про SEO оптимізацію інтернет-магазину.
5. Google бачить soft duplicate, а не повний дубль
Soft duplicate — це одна з найнеприємніших сучасних SEO-проблем.
Йдеться про сторінки, які:
- не є повними копіями;
- але дуже схожі між собою.
Наприклад:
- сторінки міст;
- SEO-сторінки послуг;
- варіації категорій;
- сторінки з мінімально переписаним текстом.
Особливо ситуація ускладнилася після масового використання AI-контенту.
Сьогодні багато сайтів генерують десятки сторінок за схожими шаблонами:
- “послуга + місто”;
- “товар + бренд”;
- “тип сайту + ніша”.
Формально тексти можуть бути різними. Але для Google вони часто виглядають як дуже близькі за змістом сторінки.
У такій ситуації пошукова система:
- самостійно вибирає канонічний урл;
- групує сторінки;
- або взагалі не індексує частину URL.
І канонічність тут часто вже не допомагає.
6. Canonical веде на сторінку, яка сама має проблеми
Це банальна, але дуже поширена помилка.
Наприклад, тег канонічний веде на сторінку:
- із редиректом;
- із noindex;
- із помилкою 404;
- закриту robots.txt;
- або на сторінку з дуже слабким контентом.
Для Google це сигнал:
Ймовірно, тег налаштований помилково.
І тоді пошуковик починає шукати іншу основну сторінку.
На великих сайтах такі проблеми часто накопичуються після:
- міграцій;
- зміни URL;
- переходу на HTTPS;
- зміни структури категорій;
- видалення товарів.
Іноді тег канонічний залишається на сторінки, яких уже давно не існує.
7. XML sitemap суперечить канонічному URL
Багато хто сприймає карту сайту лише як технічний файл. Але для Google це важливий сигнал структури сайту.
Якщо sitemap містить:
- параметри URL;
- дублікати;
- фільтри;
- pagination;
- старі адреси,
то це може прямо суперечити canonical логіці.
Наприклад:
- канонічний тег вказує на чистий URL;
- а карта сайту активно просуває URL із параметрами.
У такому випадку Google починає сумніватися:
Яка сторінка справді основна?
Особливо часто це трапляється після автоматичної генерації sitemap через SEO-плагіни.
На практиці варто регулярно перевіряти:
- які URL реально потрапляють у карту сайту;
- чи немає там технічних сторінок;
- чи не індексуються фільтри;
- чи sitemap відповідає логіці canonical.
8. Канонічність генерується занадто пізно через JavaScript
Сучасний frontend сильно змінив роботу пошукових систем.
Особливо це стосується:
- React;
- Vue;
- SPA;
- headless CMS;
- JavaScript-heavy сайтів.
У деяких випадках canonical:
- додається динамічно;
- змінюється після рендерингу;
- або взагалі з’являється лише після виконання JavaScript.
Проблема в тому, що Googlebot не завжди обробляє такі сторінки так само, як звичайний браузер користувача.
У результаті:
- канонічний урл може бути проігнорований;
- Google може побачити інший URL;
- або пошуковик взагалі не врахує динамічно згенерований тег.
На класичних WordPress-сайтах така проблема зустрічається рідше. Але в сучасному frontend-розробленні це вже дуже типова ситуація.
9. AI-контент створив нову хвилю дубльованих сторінок
Останні роки проблема канонічності стала ще складнішою через масову генерацію контенту.
Багато сайтів почали створювати:
- сотні SEO-сторінок;
- окремі сторінки під запити;
- “унікалізовані” тексти.
І хоча формально контент різний, Google усе краще розуміє:
- структуру сторінки;
- намір користувача;
- повторювані шаблони;
- схожість контенту.
У результаті пошуковик дедалі частіше:
- сам об’єднує сторінки;
- самостійно визначає канонічний урл;
- або просто не індексує частину URL.
І це вже проблема не лише технічного SEO, а загальної якості структури сайту.
10. Google просто не погоджується з вашим рішенням
Це найнеприємніша причина. Але саме вона сьогодні зустрічається дедалі частіше.
Канонічний URL — це лише один сигнал серед десятків інших.
Google також аналізує:
- внутрішні посилання;
- зовнішні посилання;
- структуру сайту;
- поведінкові сигнали;
- релевантність сторінки;
- якість контенту;
- частоту сканування URL.
І якщо алгоритми вважають іншу сторінку більш логічною як основну — тег канонічний можуть просто проігнорувати.
Особливо зараз, коли Google значно активніше:
- кластеризує сторінки;
- об’єднує дублікати;
- сам визначає структуру індексації.
Як перевірити, чи Google прийняв канонічний URL
Найкращий інструмент для цього — Google Search Console.
Саме там можна побачити:
- User-declared canonical;
- Google-selected canonical.
Якщо ці URL не збігаються — Google проігнорував ваш канонічний урл.
Додатково варто перевірити:
- XML sitemap;
- внутрішні посилання;
- hreflang;
- robots.txt;
- редиректи;
- технічні дублікати;
- параметри URL.
Для глибшого аналізу добре підходять:
- Screaming Frog;
- Ahrefs;
- Sitebulb;
- JetOctopus.
Особливо на великих сайтах такі перевірки варто робити регулярно, а не лише після появи проблем в індексації.
Іноді проблеми з канонічним URL довго залишаються непомітними, але поступово починають впливати на індексацію та видимість сайту. Google може вибирати менш релевантні сторінки, ігнорувати потрібні URL або неправильно розподіляти вагу між дублями. У результаті сайт починає втрачати позиції навіть без очевидних технічних помилок. Схожі ситуації ми також розглядали у статті чому сайт знижується в рейтингах пошуку.
Висновок
Канонічний URL більше не є “магічною кнопкою”, яка автоматично вирішує проблеми з дубльованим контентом.
Сучасні сайти стали значно складнішими:
- багатомовність;
- фільтри;
- JavaScript;
- AI-контент;
- faceted navigation;
- параметри URL;
- автоматична генерація сторінок.
У такому середовищі Google дедалі частіше самостійно визначає, яку сторінку вважати основною.
І якщо:
- структура сайту;
- sitemap;
- внутрішні посилання;
- hreflang;
- контент;
- або загальна логіка індексації
суперечать канонічному URL — одного meta tag уже недостатньо.
Сьогодні canonical працює лише як частина цілісної технічної SEO-структури сайту.
